L’intelligence artificielle, ou IA, pourrait améliorer et simplifier notre système des soins de santé en déléguant des tâches aux machines, voire en leur confiant des tâches impossibles à accomplir par des êtres humains. Aujourd’hui, dans le monde de la santé, l’IA est déjà omniprésente : à l’hôpital, pour détecter des tumeurs lors d’un scanner ; à domicile, pour indiquer avec précision la dose d’insuline à administrer à un moment précis à une personne atteinte de diabète.
Toutefois, l’IA s’accompagne également de nombreux défis. En effet, l’IA repose sur des algorithmes, c’est-à-dire un ensemble d’instructions écrites en « langage informatique » qui indiquent à une machine comment exécuter une tâche. Dans le monde des soins de santé, pour entraîner des algorithmes basés sur l’IA, nous avons généralement besoin d’un grand ensemble de données, appelées « mégadonnées » (en anglais « big data »). Cependant, nous devons veiller à ce que les données utilisées soient de bonne qualité et présentent une diversité suffisante pour englober toutes les situations potentielles auxquelles les algorithmes seront confrontés dans la pratique clinique. Malgré la complexité de la tâche, l’entraînement d’un algorithme d’IA est la partie la plus simple du processus ; le plus grand défi est de recueillir suffisamment de données de grande qualité pour que la machine apprenne à résoudre un problème correctement. Sinon, les algorithmes ne fonctionneront pas comme il faut dans certaines situations, produiront des erreurs systémiques ou généreront des résultats biaisés.
Dans le domaine de la santé, la plupart des ensembles de données ont été recueillis auprès d’hommes blancs et les algorithmes fonctionnent généralement correctement pour ce groupe spécifique. En revanche, pour d’autres groupes, p.ex. des femmes ou d’autres ethnies, nous observons parfois des biais, simplement parce l’algorithme n’a pas été entraîné correctement, faute de données suffisantes. Par conséquent, il incombe aux chercheurs en IA de valider et de tester soigneusement leurs algorithmes par rapport aux différents groupes de la population, afin que la solution puisse être utilisée en toute sécurité pour tout le monde. Ainsi, personne ne risquera de recevoir un diagnostic biaisé ou un traitement erroné parce qu’il/elle présente des caractéristiques différentes de celles de la population dont les données ont été utilisées pour entraîner l’algorithme.
Pour en savoir davantage sur ces aspects, rendez-vous sur le site-web du livre « Precision Health », développé sur l’initiative de l’Association des Ingénieurs et Scientifiques du Luxembourg par le Luxembourg Institute of Health (LIH), en étroite collaboration avec le Service de Coordination de la Recherche et de l’Innovation pédagogiques et technologiques (SCRIPT).
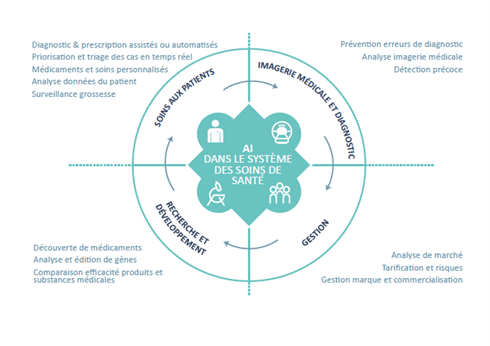
Aujourd’hui, l’intelligence artificielle est utilisée dans de nombreuses disciplines des soins de santé. Et ces possibilités ne feront que s’accroître à l’avenir. Illustration inspirée du site suivant.